A number of different artificial intelligence machine learning systems were explored in order to acquire a basic knowledge of such systems, how to train them, and what they produce, as well as an idea of their value to the Baby Bliss Bot Project. Additionally, this exploration will provide insights into the capabilities and limitations of these systems.
StyleGAN: StyleGAN2-ADA and StyleGAN3
A GAN (Generative Adversarial Network) is a machine learning framework for a type of AI that generates fake content after being trained with a large set of real data. An example is shown on the Random Face Generator (This Person Does Not Exist), a website where the images of faces that are produced are not of actual people. Instead the GAN, which has been trained on many pictures of actual faces, composes a new face based on what it has learned from its training.
Nvidia has developed a type of a progressive GAN called a StyleGAN. The system is trained first with low resolution images, and as training proceeds, higher resolutions are progressively introduced. Exploring StyleGAN models holds the promise of uncovering new Bliss characters for brainstorming.
There are several versions of StyleGAN. We investigated two of them: StyleGAN2-ADA and StyleGAN3.
StyleGAN2-ADA
The relevant aspect of StyleGAN2-ADA is that this version of StyleGAN can be trained using a small set of data. In that regard, there are only 1,216 distinct single Bliss symbols out of 6,000+ total symbols. Greyscale images of the single Bliss symbols were used as the training set. These are shown in an array of symbols in Figure 1 below.

Guided by the article How to Train StyleGAN2-ADA with Custom Dataset, a StylGAN2-ADA network was trained over several runs for a total training time of 62 hours. The following figure shows an array of the final synthesized images generated by the GAN. Note that these images do not correspond to real Bliss symbols but are produced by StyleGAN2-ADA. The GAN extracts features or patterns found in the training data and attempts to mimic Bliss symbols based on the learned features.

As can be seen, the generated images have a superficial resemblance to real Bliss symbols and it appears that the GAN has detected and learned some features or patterns present in the single Bliss symbols. At the present time it is unclear what patterns the GAN has learned exactly. This is an issue for potential future explorations of GAN machine learning models.
StyleGAN3
StyleGAN3 introduced improvements over StyleGAN2, primarily addressing the issue of aliasing in generated images. Aliasing becomes particularly noticeable when creating rotating images, resulting in a “glued” appearance of pixels that fail to rotate naturally. To overcome this problem, StyleGAN3 ensures that every layer of the synthesis network produces a continuous signal, enabling the transformation of details collectively.
Guided by the README of the StyleGAN3 PyTorch implementation and utilizing the same dataset of 1,216 single Bliss symbols used to train the StyleGAN2-ADA model, a StyleGAN3 network with config T (stylegan3-t) was trained for 240 hours. The following figure shows an array of final synthesized images generated by the trained model:

As can be seen, the generated images exhibit wild transformations and rotations based on real images. However, these generated images are not suitable for the purpose of brainstorming new Bliss symbols.
CLIP model
CLIP (Contrastive Language–Image Pre-training) comprises a machine learning technique in which images, in addition to textual information describing those images, are used in the training process. This approach has been receiving increased attention in the field of computer vision, where previous advances have provided high levels of accuracy in tasks such as the recognition and classification of objects in photographs and videos. However, it has been argued that state-of-the-art approaches in computer vision have various limitations, including for example that the systems are often able to make predictions and identification over a small number of categories, preventing the ability to identify more general and abstract features, not to mention the laborious work required in the preparation of the data when the systems are required to recognize new objects not previously included in the datasets.
The BBB Project has started experimenting with CLIP models in order to explore how the use of multimodal (images and textual) data training strategies can be applied for a better understanding of the internal composition of Bliss symbols and combined words.
For this exploration, we have created an initial annotated dataset using the existing official Bliss vocabulary database. In this dataset we have used the images of each Bliss symbol and created a set of annotations by extracting two fields contained the official Bliss database, namely the “gloss”, which includes different words and synonyms and the “explanation”, which contains a description about how one particular Bliss symbol was constructed.
At the moment, the results are still preliminary and we are not be able to determine the value of this approach until further testing is concluded. We have identified additional avenues that include for example, refining and augmenting the annotations in the Bliss dataset, fine-tuning different existing models, as well as training CLIP models from the scratch. For the moment, we can speculate that the use of CLIP based models might provide avenues for the generation of new symbols, as well as the ability of introducing advanced searching features.
YOLO
YOLO: “You only look once” is an AI strategy widely applied to real-time object detection. YOLO models are currently being used in various tasks such as the identification of objects in self-driving cars and even face recognition applications. The key goal of YOLO models is to be able to train a system in order to identify a given object in any part of an image, and as a result, provide information about the position of that object as well as a probabilistic approach to the identification of such object in a corpus of fixed categories.
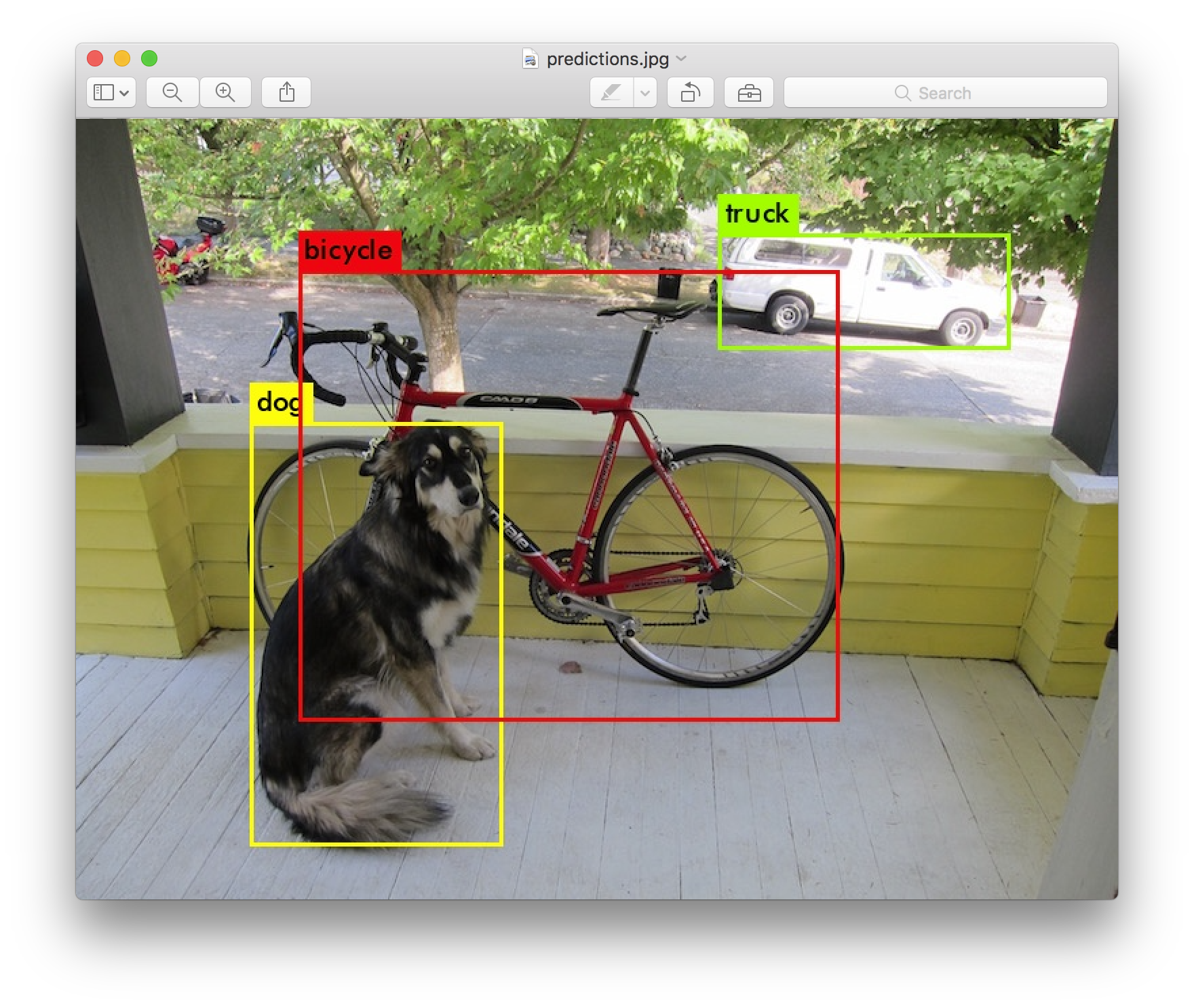
The BBB project has started an exploration with YOLO models in order to address two main challenges. The first one is the extraction of Bliss symbols contained in the large Bliss Archive. Although the data contained in the Archive has already applied Optical Character Recognition (OCR) methods, and most of the scanned documents and books are available in text format, the Bliss symbols contained in these data remain available only in image format. With the aim of exploring the possibility of training a Large Language Model (LLM) specifically to understand and generate Bliss sentences, we are considering the use and creation of YOLO models as an initial avenue for generating the data that will be needed for such Bliss LLM.
The second challenge where we see YOLO models can be useful is in the recognition of Bliss symbols in everyday life settings. With a real-time Bliss symbol recognition system that is provided with live images or video of AAC user interacting with printed Bliss boards, we envision the possibility of assisting AAC users to communicate with others that do not understand Bliss, such as care professionals or even family members that may not know certain Bliss vocabulary.
The initial steps taken in this direction are still preliminary as we have not been able yet to generate a large training dataset, due to the labor-intensive process required in labeling the data. As we move forward, we are exploring ways of automating certain parts of the process for image labeling as well as augmenting Bliss symbols data with the use of image filters which we hope can provide more robust training data.